Accuracy of an artificial intelligence chatbot in identifying congenital glaucoma from other ocular etiologies
Article Sidebar
Main Article Content
Abstract
Purpose
To evaluate the accuracy and appropriateness of responses provided by ChatGPT in identifying congenital glaucoma from a series of written and image-based prompts.
Methods
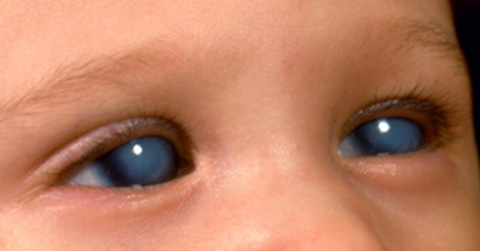
A series of questions regarding common signs and symptoms of congenital glaucoma were developed and queried to ChatGPT-3.5 and ChatGPT-4.0, and a set of publicly available images of patients with congenital glaucoma were queried to the image search function of ChatGPT-4.0. Outputs were graded by three pediatric ophthalmologists with expertise in congenital glaucoma. Completeness of response, accuracy, potential for harm, and concern for glaucoma were assessed by each reviewer.
Results
A higher proportion of prompt responses from ChatGPT-4.0 were graded to be acceptable/appropriate than from ChatGPT-3.5 (22/33 vs 9/33 [P = 0.001]) among text-based queries. A higher proportion of ChatGPT-4.0 responses were felt to raise appropriate concern for congenital glaucoma (8/11 vs 2/11 [P = 0.03]) and a lower proportion of responses had incorrect or inappropriate information of major clinical significance (0/33 vs 6/33 [P = 0.02]) than ChatGPT-3.5 responses. There was no significant difference in the proportion of responses from ChatGPT-3.5 and ChatGPT-4.0 that were deemed to have potential likelihood of harm (P = 0.17). Among clinical images queried to ChatGPT-4.0, responses to two of three images were universally felt to be unacceptable with a major amount of incorrect or inappropriate clinical information and high/definitive likelihood of harm. Among readability indices, the SMOG Index score showed more difficult readability scores for ChatGPT-4.0 than for ChatGPT-3.5 (14.8 ± 1.2 vs 14.0 ± 1.4 [P = 0.009]).
Conclusions
Despite superior performance from ChatGPT-4.0 compared with ChatGPT-3.5 in raising concern for congenital glaucoma and appropriateness of responses from text-based prompts, it performed poorly in recognizing clinical images of congenital glaucoma.
Downloads
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.




References
Haug CJ, Drazen JM. Artificial intelligence and machine learning in clinical medicine, 2023 N Engl J Med 2023;388:1201-8.
Bernstein IA, Zhang YV, Govil D, et al. Comparison of ophthalmologist and large language model chatbot responses to online patient eye care questions. JAMA Netw Open 2023;6:e2330320.
Mihalache A, Popovic MM, Muni RH. Performance of an artificial intelligence chatbot in ophthalmic knowledge assessment. JAMA Ophthalmol 2023;141:589-97.
Lyons RJ, Arepalli SR, Fromal O, Choi JD, Jain N. Artificial intelligence chatbot performance in triage of ophthalmic conditions. Can J Ophthalmol 2024;59:e301-8.
Huang AS, Hirabayashi K, Barna L, Parikh D, Pasquale LR. Assessment of a large language model’s responses to questions and cases about glaucoma and retina management. JAMA Ophthalmol 2024;142:371-5.
Momenaei B, Wakabayashi T, Shahlaee A, et al. Appropriateness and readability of chatgpt-4-generated responses for surgical treatment of retinal diseases. Ophthalmol Retina 2023;7:862-8.
Delsoz M, Raja H, Madadi Y, et al. The use of ChatGPT to assist in diagnosing glaucoma based on clinical case reports. Ophthalmol Ther 2023;12:3121-32.
Delsoz M, Madadi Y, Raja H, et al. Performance of ChatGPT in diagnosis of corneal eye diseases. Cornea 2024;43:664-70.
Potapenko I, Boberg-Ans LC, Stormly Hansen M, Klefter ON, van Dijk EHC, Subhi Y. Artificial intelligence-based chatbot patient information on common retinal diseases using ChatGPT. Acta Ophthalmol 2023;101:829-31.
Rojas-Carabali W, Cifuentes-González C, Wei X, et al. Evaluating the diagnostic accuracy and management recommendations of ChatGPT in uveitis. Ocul Immunol Inflamm 2024;32:1526-31.
Rojas-Carabali W, Sen A, Agarwal A, et al. Chatbots vs. human experts: evaluating diagnostic performance of chatbots in uveitis and the perspectives on AI adoption in ophthalmology. Ocul Immunol Inflamm 2024;32:1591-98.
Nikdel M, Ghadimi H, Tavakoli M, Suh DW. Assessment of the responses of the artificial intelligence-based chatbot ChatGPT-4 to frequently asked questions about amblyopia and childhood myopia. J Pediatr Ophthalmol Strabismus 2024;61:86-9.
Dihan Q, Chauhan MZ, Eleiwa TK, et al. Using large language models to generate educational materials on childhood glaucoma. Am J Ophthalmol 2024;265:28-38.
George L. Spaeth. Congenital glaucoma. Pediatrics 1991;88:1075-6.
Flesch R. A new readability yardstick. J Appl Psychol 1948;32:221-33.
McLaughlin GH. SMOG grading—a new readability formula. J Reading 1969;12:639-46.
Moshirfar M, Altaf AW, Stoakes IM, Tuttle JJ, Hoopes PC. Artificial intelligence in ophthalmology: a comparative analysis of GPT-3.5, GPT-4, and human expertise in answering StatPearls questions. Cureus 2023;15:e40822.
Jiao C, Edupuganti NR, Patel PA, Bui T, Sheth V. Evaluating the artificial intelligence performance growth in ophthalmic knowledge. Cureus 2023;15:e45700.
Mihalache A, Huang RS, Popovic MM, et al. Accuracy of an artificial intelligence chatbot’s interpretation of clinical ophthalmic images. JAMA Ophthalmol 2024;142:321-6.
Emsley R. ChatGPT: these are not hallucinations—they’re fabrications and falsifications. Schizophrenia (Heidelb) 2023;9:52.
Blum M. ChatGPT produces fabricated references and falsehoods when used for scientific literature search. J Card Fail 2023;29:1332-4.
Oca MC, Meller L, Wilson K, et al. Bias and inaccuracy in AI chatbot ophthalmologist recommendations. Cureus 2023;15:e45911.